


Meta’s Dangerously Carefree AI Chief
Plus: How Biden could stop the Gaza war. Inequality’s hidden hazards. China’s climate contradictions. Zoom AMA. And more!


Note: Next Friday, March 22, at 6 pm US Eastern Time, paid subscribers can join me and NZN staffer Andrew Day on a Zoom call. We’ll email the link on Monday. Last time we did one of these, I requested feedback about the newsletter and podcast, but this time it’s no-holds-barred—ask me anything!
Yann LeCun—chief AI scientist at Meta and a winner of the Turing Award, the computer science equivalent of the Nobel Prize—is even more important than he sounds.
Meta’s large language model, Llama, is—unlike OpenAI’s GPT, Google’s Gemini, and Anthropic’s Claude—open source. That means its ingredients—the billions of “weights” that result from its training and fine tuning and that subsequently guide its behavior—are publicly available. Which in turn means, among other things, that Llama can more readily be put to unintended use than those other LLMs.
Some very knowledgeable people think that if, as LLMs get more and more capable, some of them are open source, very bad things could happen. But don’t worry, says LeCun—everything will be fine. The concerns that motivate opponents of open source AI are “preposterously stupid,” he assures us.
By virtue of LeCun’s corporate position and his undeniable technical achievement, his views on the open source question are more influential than those of just about any other open source advocate in the world. So it matters whether LeCun’s brilliance extends far enough beyond his realm of technical expertise for us to trust his judgments about how AI will play out in the real world. Last week, on an episode of the Lex Fridman podcast, he gave me some doubts.
He started off by saying that the texts scanned by a state-of-the-art LLM like ChatGPT amount to “really not that much data.” Granted, it would (by his calculation) take a human being 170,000 years, working eight hours a day, to read all the texts. But, he continued, consider the amount of information that streams into the visual cortex every second: 20 megabytes. So a four-year-old has processed around 50 times as much visual data as the data in all those texts.
“What that tells you,” he said, “is that through sensory input we see a lot more information than we do through language and that despite our intuition, most of what we learn and most of our knowledge is through our observation and interaction with the real world, not through language.”
Now, it may in some sense be true that much more of our knowledge comes through non-linguistic than linguistic avenues. But the idea that the way you test that proposition is to compare the number of bytes that travel through those two avenues is… not very sophisticated. If that were true—if the amount of knowledge was accurately gauged by the amount of information needed to convey it—then a sentence you hear would contain way, way more knowledge than the exact same sentence contains when you read it.
Human language is a nearly miraculous phenomenon that takes knowledge whose acquisition required tons of raw sensory information—and, sometimes, was refined over generations of such acquisition—and compresses it into very small packages of information. The invention of writing made those packages even smaller. To use that smallness as a way of diminishing the importance of language is to get things, in a certain sense, backwards.
I don’t want to overdo the LeCun bashing. In his defense:
1) His information/knowledge conflation seems less muddled—like, 50, 60 percent less muddled—when put in the context of the conversation he was having with Fridman. (This part of the conversation was about whether large language models construct, or ever will construct, expansive and nuanced representations of reality, as the human brain does. And it’s presumably true that some kinds of representations are more likely to be instilled in machines via video training than via text training.)
2) He is not completely oblivious to the power of language. In fact, his case for open source AI rests on the importance of free speech: Just as freedom of speech prevents the government and other big actors from stifling dissent and amassing unhealthy amounts of power, open source AI, by proliferating wildly, can prevent a few Silicon Valley companies from running the world.
It’s a pretty strong argument. All signs are that large language models will increasingly shape ideas and beliefs, probably at the expense of books and magazines and, um, newsletters. And if the most powerful and useful AIs are made only by a few big companies, there is a real danger that outside-the-mainstream perspectives will get short shrift and the narratives of powerful interests will tend to prevail.
But the other side of the argument is also strong. Once there are open source versions of the next generation of large language models—in other words, once Meta and Mistral and other well-funded open-source AI companies put out models comparable to GPT-5, which should debut any month now—there is no telling what the consequences will be (in part because we don’t know how powerful those models will be). And it’s certainly possible to plausibly imagine some very bad consequences.
LeCun seems to have a limited understanding of why people worry about this. He tweets: “The *only* reason people are hyperventilating about AI risk is the myth of the "hard take-off": the idea that the minute you turn on a super-intelligent system, humanity is doomed. This is preposterously stupid and based on a *complete* misunderstanding of how everything works.”
This is a preposterously misleading depiction of reality. The anti-open-source crowd includes not just sci-fi AI doomers who worry about an AI takeover of Planet Earth, but people with more pedestrian disaster scenarios. These people may envision bad actors using AI to engineer a bioweapon or to bring the world’s financial system to a crashing halt or to blind so many satellites that a superpower freaks out and catastrophically overreacts. And they may envision not-necessarily-bad but not-sufficiently-risk-averse actors unleashing chaos inadvertently. And they may envision various other things that, like these, could happen without a “hard takeoff” being triggered by super-intelligent AI.
There’s one other concern about open source AI: It will speed up the evolution of a technology that, even without this boost, will bring destabilizing change that takes time to adapt to. This actually isn’t a big talking point on the anti-open-source side, but I think it should be. When people complain that some proposed regulation could slow the evolution of AI, I say that’s a feature, not a bug.
Yann LeCun made his big scientific mark in the field of visual information processing. So it’s not surprising that he tends to emphasize the power of pixels and images more than the power of words. And, again, he’s far from oblivious to the power of words. But I’m not sure he fully grasps the nature of that power. Consider this utterance on the Fridman podcast:
We cannot afford those [AI] systems to come from a handful of companies on the west coast of the US, because those systems will constitute the repository of all human knowledge and we cannot have that be controlled by a small number of people… It has to be diverse for the same reason the Press has to be diverse.
A valid point! But, however important the knowledge-storing aspect of LLMs, focusing too tightly on it misses a big part of the picture. An LLM of the future may be able to appraise its conversation partners so acutely (having processed their entire social media histories in a nanosecond or so), as to be preternaturally persuasive. And that skill, in addition to making these AIs potent political tools, will make them excellent recruiters—recruiters who can lure people into violent extremist groups, crazy cults, and so on.
LeCun’s bigger emphasis on LLMs as a knowledge repository than as a tool of manipulation is mirrored in the way he thinks about an earlier infotech breakthrough, the printing press—and, in particular, its role in fomenting the Protestant Reformation. On the Fridman podcast he takes the common view that the key impact of the printing press was to give lay Christians access to the Bible, which empowered them to challenge the church’s interpretations of scripture. I argue in my book Nonzero that the key impact was to allow Martin Luther to cheaply and broadly distribute his subversive and sometimes inflammatory tracts. (Luther really knew how to push people’s buttons.)
Here’s something that may surprise you: I’m actually an open source agnostic; I don’t yet have a well fleshed out view on the very complex question of how, or even whether, to regulate open source AI. Indeed, just to give you a sense for the issue’s complexity: The manipulative power of language is something that could be enlisted on both sides of the open source argument. It’s scary to imagine zillions of different bots organizing different crazy cults, but it’s also scary to imagine Big Brother monopolizing the tools of AI-mediated manipulation.
So the reason I’m being hard on LeCun’s casual attitude toward the open source question isn’t because I’m sure regulatory action is in order; it’s because I’m sure debate about regulatory action is in order. The arguments against open source are strong enough to get their day in court, and they need to get that day now, because if they’re right, then later could be too late. Yet almost everyone in Congress seems to share LeCun’s nonchalance.
But that could change. In late 2022 the State Department commissioned a report on AI risk, and last month the report was completed. It recommends that the US government “urgently explore” ways to restrict the release of powerful open-source AI models. That recommendation could be, if nothing else, a conversation starter. So maybe we’ll finally have the challenging and complicated debate about artificial intelligence that Yann LeCun thinks is a no brainer.
P.S. I did a fairly deep dive on open source AI in the Nonzero podcast episode released today. My guest was Nathan Labenz, who hosts the highly regarded Cognitive Revolution podcast. He offered a lot of insight into the issue.

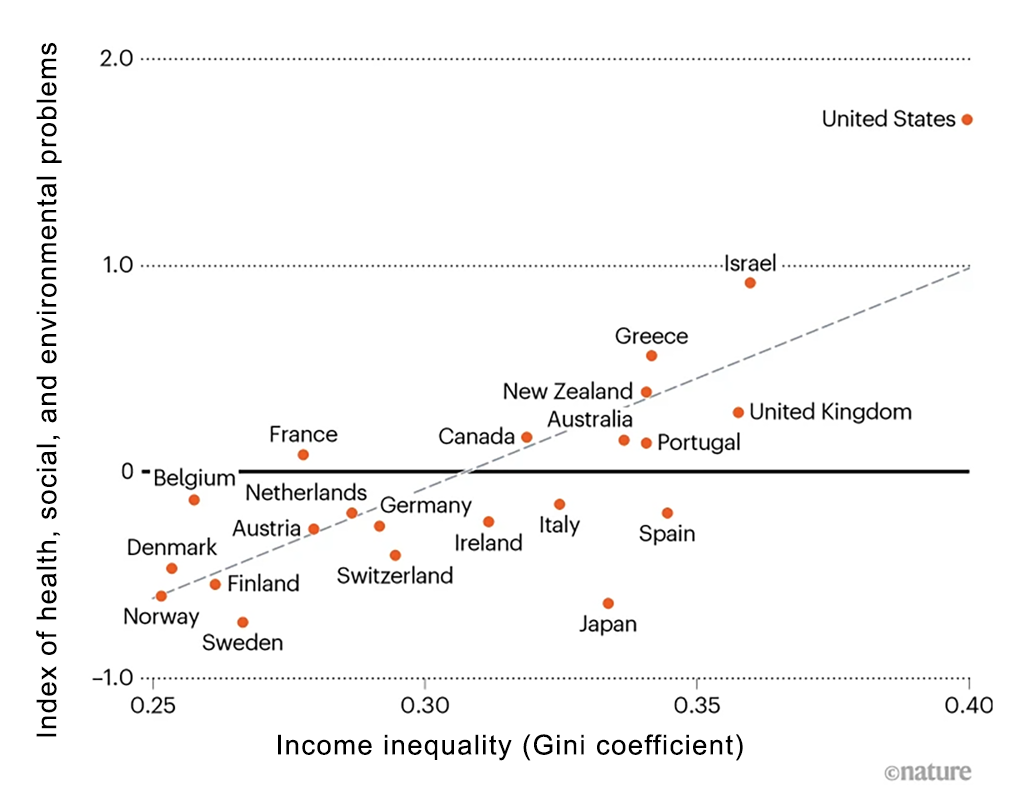
The trouble with income inequality goes well beyond the inequality itself, according to a study released this week by Nature. The study found that “nations with large gaps between rich and poor tend to have worse health statistics, more violence and worse pollution than do more-equal countries.” And though, as the saying goes, “correlation isn’t causation,” the authors argue that in this case there is a plausible causal link.

Does President Biden have enough leverage with Israel to get a ceasefire in Gaza? This week, British-Israeli political analyst Daniel Levy came on the Nonzero podcast and argued in the affirmative. Levy, who was involved in both the Camp David (2000) and Taba (2001) negotiations with the Palestinian Authority, recommends these two steps:
1) Put forward a specific “bridging proposal” that both Hamas and the Israeli government could reasonably accept. This would activate pro-ceasefire elements in the military, the political establishment, and society broadly. “You will have the war cabinet divided. You will have the public divided; you will see, I think, an escalation in what already has been a shift in the willingness to protest…”
2) Be “willing to use the most crucial piece of leverage that they [Biden administration officials] have—which is, of course, the provision of arms, ordnance, the weaponry without which this couldn’t continue… If you’re not willing to put that on the table, as the United States government, don’t tell me that you don’t want to see another 30,000 dead.” Levy added that the threat to withhold weapons if Israel is intransigent should be made publicly to increase its credibility.
You can watch or listen to the episode—including the Overtime segment—here. And if you want to help us expand the audience for conversations like this, please rate and review the Nonzero podcast on your podcast app, spread the word on social media, and perhaps occasionally smash (don’t just click—smash!) the like button on the YouTube versions of the podcast.